At the moment, all our projects are built on Python. Before we formally enter into any specific topic or model buildings, I think it might be necessary to write a post, help those who are new to Python to quickly set up the environment for further analysis, introduce some libraries and learning resources for further reading. Later in the future, I will also post relevant set-up for C++.
Introduction
Python is a high-level OOP (Object-Oriented Programming) language and an elegant toolkit for data science, with so many open source libraries. We can easily inherit from their modules and classes for our own implementation. Though Python can do anything, we will focused on the data science, data analysis, model training, ML/DL now.
In this post, I will help you setup your local Python environment and introduce libraries for the financial machine learning/time series project. Please note that I won’t teach the basic data-structure like list, dict, tuple, set, str or basic algorithm logic like for-loop, while-loop.
If you are totally new to Python, I would strongly recommend you take online courses on dataquest.io or datacamp, both websites allow you to learn from the lectures and implement on the web-based Python kernel, so you can read and code in the same time with focus on the coding and logic instead of those annoying programming setting in the first place. (For this topic or anything around data science/data analysis, master pandas would be highly-recommended)
Those convenient learning resources is also one of the pros of Python. I didn’t find any such website for C++ or Java yet (which allows you to code near around). Another online course on Giraffe Academy is nice, check it out if you like (actually I learned to write this post on Hexo from Mike XD)
Setup Python Environment
Programming environment is important to your project, we will need Anaconda environment manager to setup our environment for the research.
First, make sure you download the latest version Here, then install it and open Anaconda Prompt, use conda in command line, reference: Anaconda cheatsheet
Use the following command code in Anaconda Prompt to create an new environment and install packages:
1 | $ conda create -n <my_env> python=3.6 |
Then you can activate your environment and install packages using:
1 | $ activate <my_env> |
Now we are all good, install the necessary packages like pandas, numpy, scipy, sklearn, matplotlib and so on, with conda or pip in your environment.
IDE
Many IDEs are available for Python, here I only recommend the most powerful two - Jupyter Notebook/Lab and Pycharm.
Jupyter Notebook (Now new version Jupyter Lab available!)
Awesome light-weight IDE which allows us to build elegant markdown with code cell by cell. You can write in HTML or LATEX to customize your page, export them in to html page or PDF!

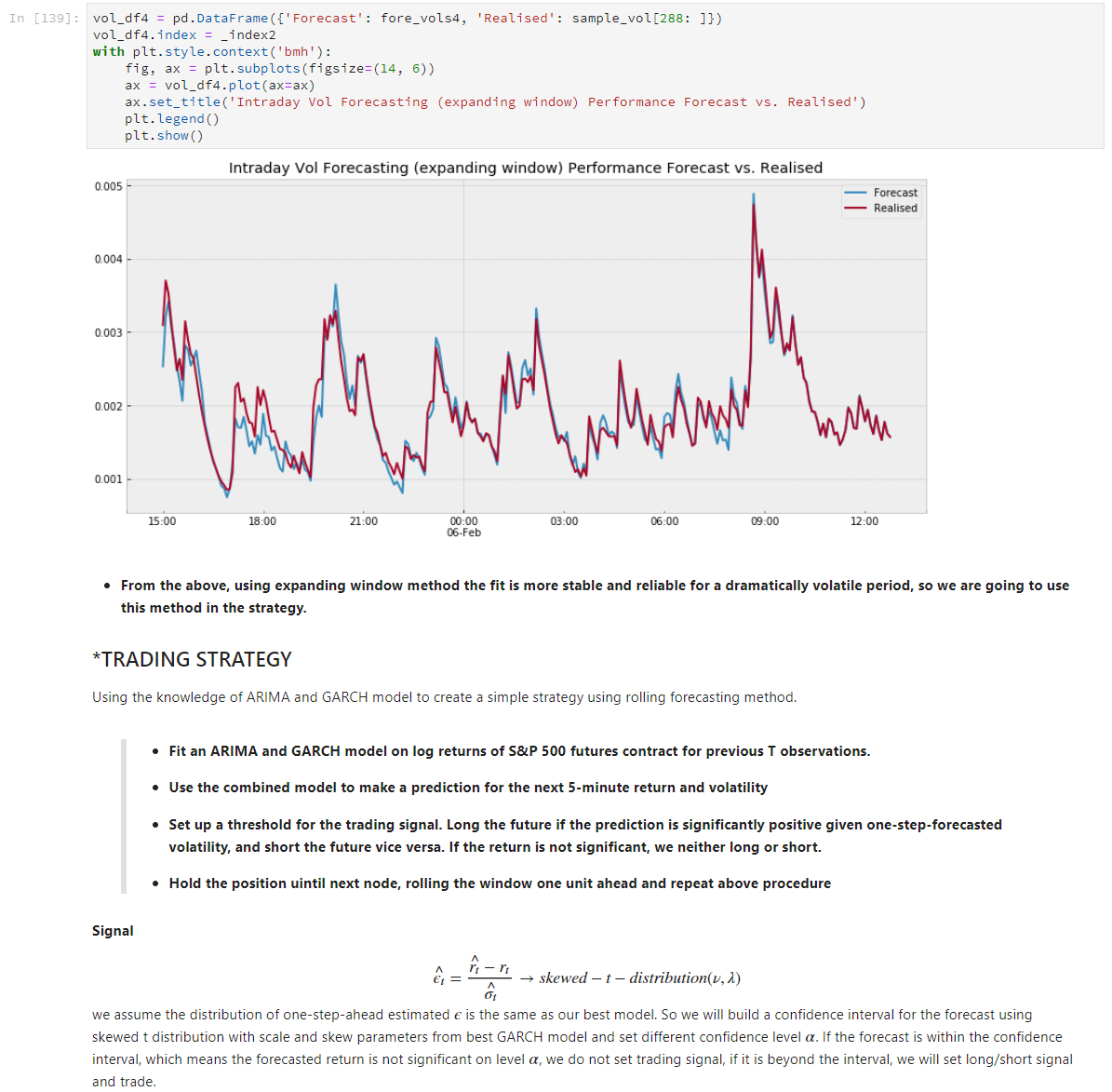
Here is an snippet of my project in notebook
Pycharm
An very professional IDE for Python development, powerful version control with Git, effective in teamwork. Actually, In the NYU Future Labs where I worked, I don’t see any other Python development IDE are used among all start-up tech companies other than Pycharm.
The combination of those two toolkits would prepare us for advanced quantitative research.
A typical workflow for a Quant as the following: you develop modules, write classes and build packages, play with big data, run the experiments on Pycharm (which nicely supports multi-processing), then analyze the result/data/model-output effectively (with lots of visualization) on Jupyter notebook, show them to your boss.
Open Source Libraries
Python can do anything! In the following, I list some common though very powerful packages that I strongly recommend you to install in the first place for statistical analysis, ML/DL.
As the posts go along, I will introduce more are more packages which are focused on specific jobs such as feature extraction, feature selection, time series prediction, etc.
Data
Numpy
The first nice library to deal with data, nice data-structure which supports high-dimention data, often used for other advanced libraries such as Sklearn, Keras, etc.
Pandas
The most important library in our project of all time! Pandas could be used to deal with ANY excel-liked data, with powerful data-structure such as pd.DataFrame and pd.Series and hundreds of easy-to-use, C++ speed level functions to transform your table. Supports datetime object which is especially powerful to deal with time series data.
You will probably find the most common two import lines in almost every code snippet online:
1 | import pandas as pd |
Machine Learning/Deep Learning
Sklearn
The most powerful and easy-to-use machine learning library, includes feature scaling, feature decomposition, metrics analysis, cross-validation, model training for both regression, clustering, classification. Forecasting could be made in 3 lines of code. e.g.
1 | from sklearn.ensemble import RandomForestRegressor |
Well-organized code structure allows us to inherit from sk-learn class for the implementations on our own.
Tensorflow, Keras
Advanced deep learning libraries to deal with, I will implement RNN, LSTM on sequential model later in the posts.
Data Visualization
Matplotlib
Underlying library to deal with plotting in Python. You can build beautiful plots and nicely aligned profile. The basic structure is ax and figure, which represents single plot and plot background (blackboard).
Seaborn
Library based on Matplotlib with some very nice plot type for statistical analysis, e.g. heatmap, which can be used to plot by rank/decile/correlation to capture important pattern , we will discuss in the later posts.

an customized plot from one of my project
Others
tsfresh
A very handful light-weighted library to extract features in a time series, by single one line code, we could extract 794 features including fast-fourier transformation, wavelet transformation, linear trend, quantiles transformation, etc. We will go into details on this library later.
statsmodels
Library to deal with statistical models, I used to build ARIMA, GARCH type, EWMA, etc. models with this package, similar to what is been used in R, both have very nice model summary profile.
pyflux
Library focused on time series modeling, similar to statsmodels.tsa.
fbprophet
Library to help you automatically forecast time series from history by facebook, especially useful for traditional time series model with seasonal pattern.
Advices
Documentations and source code are of great importance to learn a new language, you will find yourself diving into docs. or source code when facing with trying to solve a specific problem or to learn new packages. Stack-Overflow is an awesome community for programming, when you have no idea how to implement the issue or run into errors, you can simply google your problem, the first a few pop-ups are often from someone asking the same questions in Stack-Overflow. Check it before you decide to solve by yourself, it will save you lots of time.
You will also need to learn Github structure when you are using Pycharm. Basically speaking, Github is a cloud where you can manage version-control of your personal/teamwork projects by uploading push and downloading pull your code, creating new branch, etc. You can clone any open-source code to your local environment or store and share your own code by this logic on Github.
Documentation page of `tsfresh`
Summary
Now you have already setup the basic environment as a Quant. From the next post, we will dive into real problems and try to solve them by quantitative analysis on Python. Thank you for reading. If you like this post, share it with your friends: )